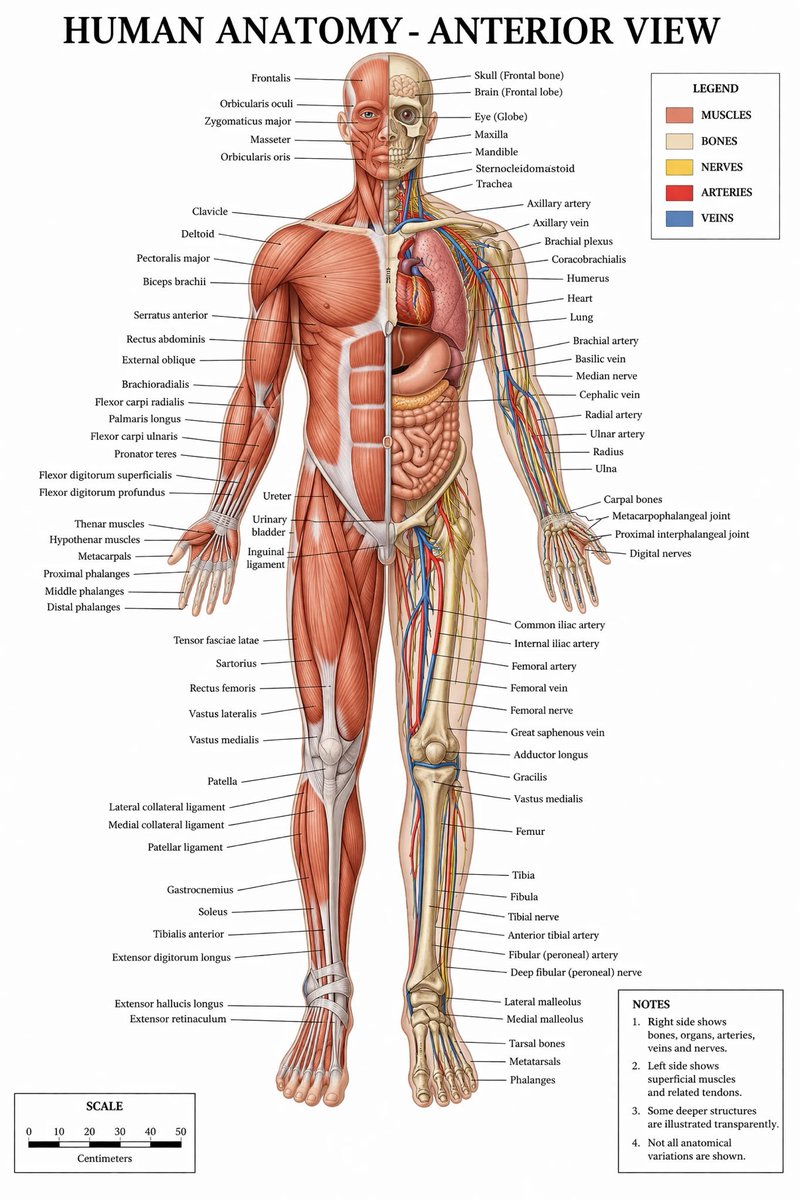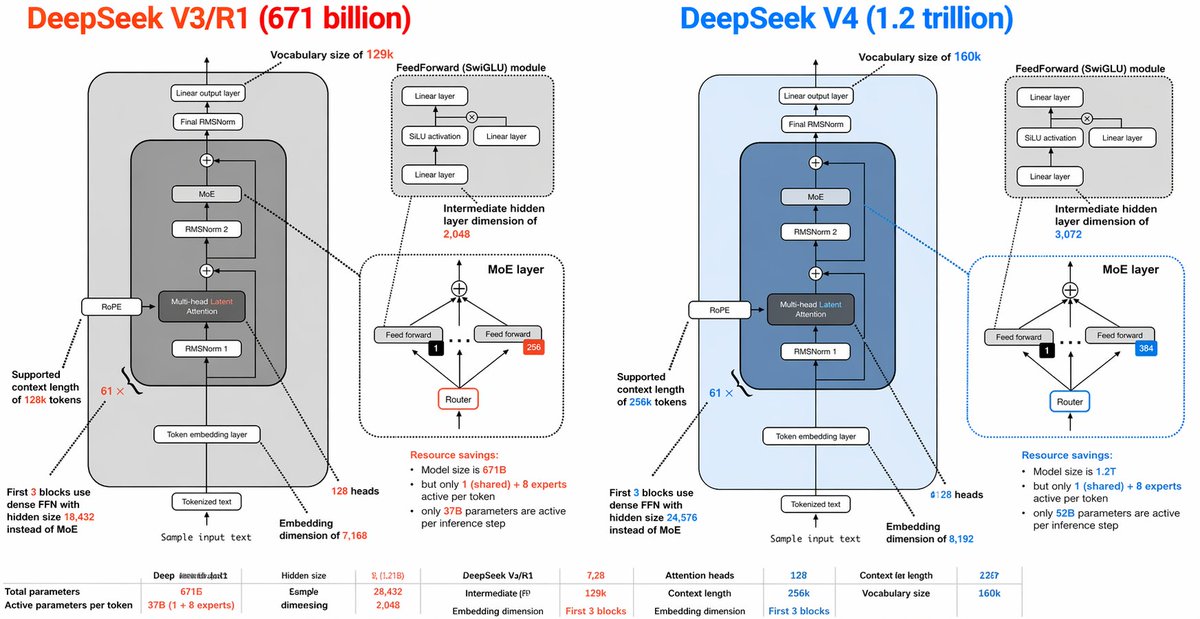
DeepSeek V3 与 V4 架构对比信息图
一份详尽的并排技术信息图,对比了 DeepSeek V3/R1 与 DeepSeek V4 的 Transformer 架构,适用于社交媒体发布、演示文稿或模型分析可视化。
- Category
- Charts & Infographics
- Model
- GPT Image 2
- Creator
- Sigrid Jin 🌈🙏
- Source language
- en
- Source ID
- 15614
- Published
- Apr 24, 2026
Full prompt
{"type":"side-by-side AI architecture comparison infographic","style":"clean technical diagram, white background, thin black outlines, rounded rectangles, dashed callout boxes, color-coded highlights, presentation-slide aesthetic, vector infographic","canvas":{"aspect_ratio":"2:1","resolution":"wide horizontal"},"title_row":{"left_title":"DeepSeek V3/R1 (671 billion)","right_title":"DeepSeek V4 (1.2 trillion)","left_title_color":"bright orange-red","right_title_color":"bright blue"},"layout":{"columns":2,"sections":[{"title":"DeepSeek V3/R1 (671 billion)","position":"left half","count":9,"labels":["Vocabulary size of 129k","FeedForward (SwiGLU) module","Intermediate hidden layer dimension of 2,048","MoE layer","Supported context length of 128k tokens","First 3 blocks use dense FFN with hidden size 18,432 instead of MoE","Sample input text","Embedding dimension of 7,168","128 heads"]},{"title":"DeepSeek V4 (1.2 trillion)","position":"right half","count":9,"labels":["Vocabulary size of 160k","FeedForward (SwiGLU) module","Intermediate hidden layer dimension of 3,072","MoE layer","Supported context length of 256k tokens","First 3 blocks use dense FFN with hidden size 24,576 instead of MoE","Sample input text","Embedding dimension of 8,192","128 heads"]},{"title":"bottom comparison table","position":"bottom full width","count":10,"labels":["Total parameters","Active parameters per token","Hidden size","Esmple dimesiegn","DeepSeek V3/R1","Intermediate (FF)","Attention heads","Context length","Embedding dimension","Vocabulary size"]}]},"left_panel":{"background":"very light gray rounded rectangle","main_stack":{"count":8,"blocks":["Tokenized text","Token embedding layer","RMSNorm 1","Multi-head Latent Attention","RMSNorm 2","MoE","Final RMSNorm","Linear output layer"]},"side_module":"RoPE attached to the attention block on the left side","attention_block":{"label":"Multi-head Latent Attention","accent":"orange-red text for the word Latent"},"feedforward_inset":{"title":"FeedForward (SwiGLU) module","count":4,"blocks":["Linear layer","SiLU activation","Linear layer","Linear layer"],"diagram":"two branches multiplied, then projected"},"moe_inset":{"title":"MoE layer","count":5,"blocks":["top combine node","Feed forward","Feed forward","Router","expert count badge 256"],"details":"small black square with 1 selected expert, arrows routing upward to experts, dotted divider line"},"annotations":{"vocab":"Vocabulary size of 129k","ff_dim":"Intermediate hidden layer dimension of 2,048","context":"Supported context length of 128k tokens","dense_first_blocks":"First 3 blocks use dense FFN with hidden size 18,432 instead of MoE","resource_savings":"Resource savings: Model size is 671B but only 1 (shared) + 8 experts active per token; only 37B parameters are active per inference step"},"bottom_stats":{"count":10,"items":["Total parameters: 671B","Active parameters per token: 37B (1 + 8 experts)","Hidden size: 7,128","Esmple dimesiegn: 28,432","Intermediate (FF): 2,048","Attention heads: 128","Context length: 128k","Embedding dimension: First 3 blocks","Context ler length: 22G7","Vocabulary size: 129k"]}},"right_panel":{"background":"very light blue rounded rectangle","main_stack":{"count":8,"blocks":["Tokenized text","Token embedding layer","RMSNorm 1","Multi-head Latent Attention","RMSNorm 2","MoE","Final RMSNorm","Linear output layer"]},"side_module":"RoPE attached to the attention block on the left side","attention_block":{"label":"Multi-head Latent Attention","accent":"blue text for the word Latent"},"feedforward_inset":{"title":"FeedForward (SwiGLU) module","count":4,"blocks":["Linear layer","SiLU activation","Linear layer","Linear layer"],"diagram":"same structure as left panel"},"moe_inset":{"title":"MoE layer","count":5,"blocks":["top combine node","Feed forward","Feed forward","Router","expert count badge 384"],"details":"small black square with 1 selected expert, arrows routing upward to experts, dotted divider line, blue border emphasis"},"annotations":{"vocab":"Vocabulary size of 160k","ff_dim":"Intermediate hidden layer dimension of 3,072","context":"Supported context length of 256k tokens","dense_first_blocks":"First 3 blocks use dense FFN with hidden size 24,576 instead of MoE","resource_savings":"Resource savings: Model size is 1.2T but only 1 (shared) + 8 experts active per token; only 52B parameters are active per inference step"},"bottom_stats":{"count":10,"items":["Total parameters: 1.2T","Active parameters per token: 52B (1 + 8 experts)","Hidden size: 7,2B","Esmple dimesiegn: 28,432","Intermediate (FF): 3,072","Attention heads: 128","Context length: 256k","Embedding dimension: First 3 blocks","Context ler length: 22G7","Vocabulary size: 160k"]}},"global_notes":"Create a highly detailed transformer architecture comparison diagram with mirrored layouts. Each half contains one large model stack diagram plus 2 inset diagrams: 1 feedforward module and 1 MoE layer. Use arrows between blocks, tiny technical labels, and connector lines from labels to the relevant components. Keep the typography dense and slide-like, with orange-red used for all V3/R1 emphasis and blue used for all V4 emphasis. Include a small bottom row of compact tabular metrics spanning the width. Preserve the slightly imperfect, human-made infographic look with very small text and crowded annotations."}Translations
DeepSeek V3 与 V4 架构对比信息图
en{"type":"side-by-side AI architecture comparison infographic","style":"clean technical diagram, white background, thin black outlines, rounded rectangles, dashed callout boxes, color-coded highlights, presentation-slide aesthetic, vector infographic","canvas":{"aspect_ratio":"2:1","resolution":"wide horizontal"},"title_row":{"left_title":"DeepSeek V3/R1 (671 billion)","right_title":"DeepSeek V4 (1.2 trillion)","left_title_color":"bright orange-red","right_title_color":"bright blue"},"layout":{"columns":2,"sections":[{"title":"DeepSeek V3/R1 (671 billion)","position":"left half","count":9,"labels":["Vocabulary size of 129k","FeedForward (SwiGLU) module","Intermediate hidden layer dimension of 2,048","MoE layer","Supported context length of 128k tokens","First 3 blocks use dense FFN with hidden size 18,432 instead of MoE","Sample input text","Embedding dimension of 7,168","128 heads"]},{"title":"DeepSeek V4 (1.2 trillion)","position":"right half","count":9,"labels":["Vocabulary size of 160k","FeedForward (SwiGLU) module","Intermediate hidden layer dimension of 3,072","MoE layer","Supported context length of 256k tokens","First 3 blocks use dense FFN with hidden size 24,576 instead of MoE","Sample input text","Embedding dimension of 8,192","128 heads"]},{"title":"bottom comparison table","position":"bottom full width","count":10,"labels":["Total parameters","Active parameters per token","Hidden size","Esmple dimesiegn","DeepSeek V3/R1","Intermediate (FF)","Attention heads","Context length","Embedding dimension","Vocabulary size"]}]},"left_panel":{"background":"very light gray rounded rectangle","main_stack":{"count":8,"blocks":["Tokenized text","Token embedding layer","RMSNorm 1","Multi-head Latent Attention","RMSNorm 2","MoE","Final RMSNorm","Linear output layer"]},"side_module":"RoPE attached to the attention block on the left side","attention_block":{"label":"Multi-head Latent Attention","accent":"orange-red text for the word Latent"},"feedforward_inset":{"title":"FeedForward (SwiGLU) module","count":4,"blocks":["Linear layer","SiLU activation","Linear layer","Linear layer"],"diagram":"two branches multiplied, then projected"},"moe_inset":{"title":"MoE layer","count":5,"blocks":["top combine node","Feed forward","Feed forward","Router","expert count badge 256"],"details":"small black square with 1 selected expert, arrows routing upward to experts, dotted divider line"},"annotations":{"vocab":"Vocabulary size of 129k","ff_dim":"Intermediate hidden layer dimension of 2,048","context":"Supported context length of 128k tokens","dense_first_blocks":"First 3 blocks use dense FFN with hidden size 18,432 instead of MoE","resource_savings":"Resource savings: Model size is 671B but only 1 (shared) + 8 experts active per token; only 37B parameters are active per inference step"},"bottom_stats":{"count":10,"items":["Total parameters: 671B","Active parameters per token: 37B (1 + 8 experts)","Hidden size: 7,128","Esmple dimesiegn: 28,432","Intermediate (FF): 2,048","Attention heads: 128","Context length: 128k","Embedding dimension: First 3 blocks","Context ler length: 22G7","Vocabulary size: 129k"]}},"right_panel":{"background":"very light blue rounded rectangle","main_stack":{"count":8,"blocks":["Tokenized text","Token embedding layer","RMSNorm 1","Multi-head Latent Attention","RMSNorm 2","MoE","Final RMSNorm","Linear output layer"]},"side_module":"RoPE attached to the attention block on the left side","attention_block":{"label":"Multi-head Latent Attention","accent":"blue text for the word Latent"},"feedforward_inset":{"title":"FeedForward (SwiGLU) module","count":4,"blocks":["Linear layer","SiLU activation","Linear layer","Linear layer"],"diagram":"same structure as left panel"},"moe_inset":{"title":"MoE layer","count":5,"blocks":["top combine node","Feed forward","Feed forward","Router","expert count badge 384"],"details":"small black square with 1 selected expert, arrows routing upward to experts, dotted divider line, blue border emphasis"},"annotations":{"vocab":"Vocabulary size of 160k","ff_dim":"Intermediate hidden layer dimension of 3,072","context":"Supported context length of 256k tokens","dense_first_blocks":"First 3 blocks use dense FFN with hidden size 24,576 instead of MoE","resource_savings":"Resource savings: Model size is 1.2T but only 1 (shared) + 8 experts active per token; only 52B parameters are active per inference step"},"bottom_stats":{"count":10,"items":["Total parameters: 1.2T","Active parameters per token: 52B (1 + 8 experts)","Hidden size: 7,2B","Esmple dimesiegn: 28,432","Intermediate (FF): 3,072","Attention heads: 128","Context length: 256k","Embedding dimension: First 3 blocks","Context ler length: 22G7","Vocabulary size: 160k"]}},"global_notes":"Create a highly detailed transformer architecture comparison diagram with mirrored layouts. Each half contains one large model stack diagram plus 2 inset diagrams: 1 feedforward module and 1 MoE layer. Use arrows between blocks, tiny technical labels, and connector lines from labels to the relevant components. Keep the typography dense and slide-like, with orange-red used for all V3/R1 emphasis and blue used for all V4 emphasis. Include a small bottom row of compact tabular metrics spanning the width. Preserve the slightly imperfect, human-made infographic look with very small text and crowded annotations."}
DeepSeek V3 与 V4 架构对比信息图
zh-CN{"type":"并排 AI 架构对比信息图","style":"简洁的技术图表,白色背景,细黑色轮廓,圆角矩形,虚线标注框,颜色编码高亮,演示文稿风格,矢量信息图","canvas":{"aspect_ratio":"2:1","resolution":"宽横向"},"title_row":{"left_title":"DeepSeek V3/R1 (6710 亿参数)","right_title":"DeepSeek V4 (1.2 万亿参数)","left_title_color":"亮橙红色","right_title_color":"亮蓝色"},"layout":{"columns":2,"sections":[{"title":"DeepSeek V3/R1 (6710 亿参数)","position":"左半部分","count":9,"labels":["词汇表大小 129k","FeedForward (SwiGLU) 模块","中间隐藏层维度 2,048","MoE 层","支持 128k token 上下文长度","前 3 个块使用隐藏大小为 18,432 的密集 FFN 而非 MoE","示例文本输入","嵌入维度 7,168","128 个注意力头"]},{"title":"DeepSeek V4 (1.2 万亿参数)","position":"右半部分","count":9,"labels":["词汇表大小 160k","FeedForward (SwiGLU) 模块","中间隐藏层维度 3,072","MoE 层","支持 256k token 上下文长度","前 3 个块使用隐藏大小为 24,576 的密集 FFN 而非 MoE","示例文本输入","嵌入维度 8,192","128 个注意力头"]},{"title":"底部对比表","position":"底部全宽","count":10,"labels":["总参数量","每个 token 的活跃参数量","隐藏层大小","示例维度","DeepSeek V3/R1","中间层 (FF)","注意力头","上下文长度","嵌入维度","词汇表大小"]}]},"left_panel":{"background":"浅灰色圆角矩形","main_stack":{"count":8,"blocks":["Token 化文本","Token 嵌入层","RMSNorm 1","多头潜在注意力 (MLA)","RMSNorm 2","MoE","最终 RMSNorm","线性输出层"]},"side_module":"RoPE 连接到左侧的注意力块","attention_block":{"label":"多头潜在注意力 (MLA)","accent":"Latent 一词使用橙红色文字"},"feedforward_inset":{"title":"FeedForward (SwiGLU) 模块","count":4,"blocks":["线性层","SiLU 激活函数","线性层","线性层"],"diagram":"两个分支相乘,然后进行投影"},"moe_inset":{"title":"MoE 层","count":5,"blocks":["顶部组合节点","前馈网络","前馈网络","路由","专家计数徽章 256"],"details":"带有 1 个选中专家的小黑方块,箭头指向专家,虚线分隔符"},"annotations":{"vocab":"词汇表大小 129k","ff_dim":"中间隐藏层维度 2,048","context":"支持 128k token 上下文长度","dense_first_blocks":"前 3 个块使用隐藏大小为 18,432 的密集 FFN 而非 MoE","resource_savings":"资源节省:模型大小为 671B,但每个 token 仅激活 1 个(共享)+ 8 个专家;每次推理步骤仅激活 37B 参数"},"bottom_stats":{"count":10,"items":["总参数量:671B","每个 token 活跃参数:37B (1 + 8 个专家)","隐藏层大小:7,128","示例维度:28,432","中间层 (FF):2,048","注意力头:128","上下文长度:128k","嵌入维度:前 3 个块","上下文长度:22G7","词汇表大小:129k"]}},"right_panel":{"background":"浅蓝色圆角矩形","main_stack":{"count":8,"blocks":["Token 化文本","Token 嵌入层","RMSNorm 1","多头潜在注意力 (MLA)","RMSNorm 2","MoE","最终 RMSNorm","线性输出层"]},"side_module":"RoPE 连接到左侧的注意力块","attention_block":{"label":"多头潜在注意力 (MLA)","accent":"Latent 一词使用蓝色文字"},"feedforward_inset":{"title":"FeedForward (SwiGLU) 模块","count":4,"blocks":["线性层","SiLU 激活函数","线性层","线性层"],"diagram":"与左侧面板结构相同"},"moe_inset":{"title":"MoE 层","count":5,"blocks":["顶部组合节点","前馈网络","前馈网络","路由","专家计数徽章 384"],"details":"带有 1 个选中专家的小黑方块,箭头指向专家,虚线分隔符,蓝色边框强调"},"annotations":{"vocab":"词汇表大小 160k","ff_dim":"中间隐藏层维度 3,072","context":"支持 256k token 上下文长度","dense_first_blocks":"前 3 个块使用隐藏大小为 24,576 的密集 FFN 而非 MoE","resource_savings":"资源节省:模型大小为 1.2T,但每个 token 仅激活 1 个(共享)+ 8 个专家;每次推理步骤仅激活 52B 参数"},"bottom_stats":{"count":10,"items":["总参数量:1.2T","每个 token 活跃参数:52B (1 + 8 个专家)","隐藏层大小:7,2B","示例维度:28,432","中间层 (FF):3,072","注意力头:128","上下文长度:256k","嵌入维度:前 3 个块","上下文长度:22G7","词汇表大小:160k"]}},"global_notes":"创建一个高度详细的 Transformer 架构对比图,采用镜像布局。每一半包含一个大型模型堆栈图和 2 个插图:1 个前馈模块和 1 个 MoE 层。在块之间使用箭头,添加微小的技术标签,并使用连接线将标签指向相关组件。保持排版紧凑且具有演示文稿感,所有 V3/R1 的强调使用橙红色,所有 V4 的强调使用蓝色。在底部包含一行跨越全宽的紧凑指标表。保留略显不完美的手绘信息图风格,文字较小且标注密集。"}