AI 基础设施信息图海报
一张内容详实、充满未来感的教育海报,旨在解析现代 AI 系统。适用于技术演示、学习资料及社交媒体科普。
- 分类
- 图表信息图
- 模型
- GPT Image 2
- 来源作者
- ben.oi 🌐
- 原始语言
- en
- 来源 ID
- 20861
- 发布时间
- 2026年5月16日
完整提示词
目标:制作一张制作精良的纵向教育信息图,标题为 {argument name="headline text" default="AI 基础设施"},副标题为 {argument name="subtitle text" default="现代 AI 系统的工作原理"},深入解析从数据流水线、GPU 训练集群到推理服务、批处理及 KV Cache 的现代 AI 基础设施。
画布:纵向海报,4:5 比例,深蓝色未来感数据中心风格。背景采用发光的蓝/紫色网络栅格,配以山脉、服务器机架、GPU 芯片插图、霓虹电路轨迹、纤细的圆角面板、白色与青色字体,以及橙色的小型编号徽标。整体外观应呈现出高端技术说明海报的质感,内容密集但易于阅读。
布局:左上方为大标题,下方为小标题和标语,右上方为装饰性的服务器机架和 GPU 芯片。将内容划分为 8 个带编号的主板块,右侧设置“关键概念”栏,底部为流程页脚。使用精确的面板边框、小图标、箭头、图表、表格和微标签。
板块及所需内容:
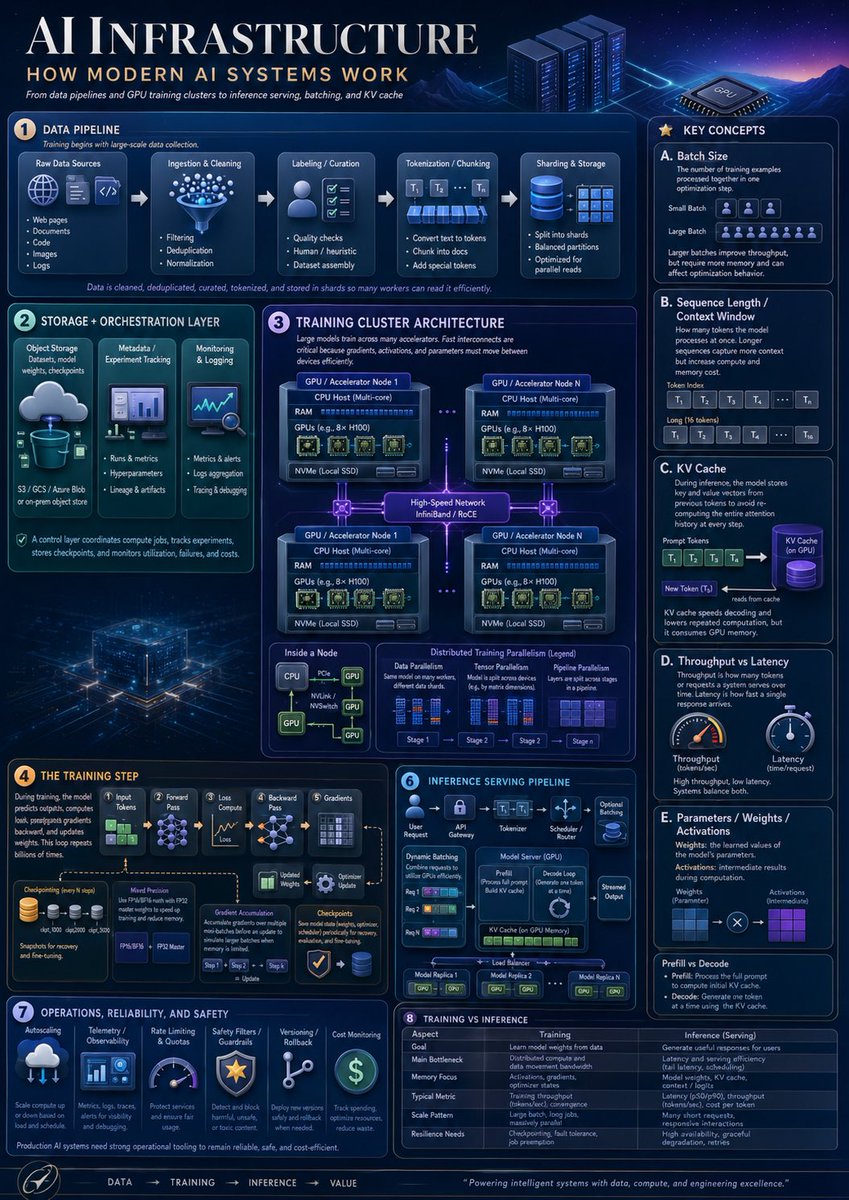
1. 数据流水线:展示 5 个由箭头连接的流水线阶段:原始数据源、摄取与清洗、标注/整理、分词/分块、分片与存储。原始数据源包含 5 个要点:网页、文档、代码、图像、日志。摄取与清洗包含 3 个要点:过滤、去重、归一化。标注/整理包含 3 个要点:质量检查、人工/启发式、数据集组装。分词/分块包含 3 个要点:转换为 Token、分块为文档、添加特殊 Token。分片与存储包含 3 个要点:拆分为分片、均衡分区、针对并行读取优化。添加说明文字,指出数据经过清洗、去重、整理、分词并存储为分片,以便多个工作节点高效读取。
2. 存储与编排层:包含 3 张纵向卡片:对象存储(配云到数据库图标,标注“S3 / GCS / Azure Blob 或本地对象存储”);元数据/实验追踪(配仪表盘图标,要点:“运行与指标”、“超参数”、“血缘与工件”);监控与日志(配图表/放大镜图标,要点:“指标与警报”、“日志聚合”、“追踪与调试”)。添加页脚说明:控制层负责协调计算任务、追踪实验、存储检查点并监控利用率、故障及成本。
3. 训练集群架构:中央大型架构图,标题为“训练集群架构”。展示 4 个 GPU/加速器节点框,呈 2x2 网格排列,通过发光的高速网络链路连接,标注为“高速网络 InfiniBand / RoCE”。每个节点包含 CPU 主机(多核)、RAM、GPU(如 8x H100)及 NVMe 本地 SSD。节点间添加虚线连接。下方包含 3 个小型面板:节点内部、数据并行、分布式训练并行(图例)。节点内部应显示 CPU 通过 PCIe/NVLink/NVSwitch 线连接至多个 GPU。分布式训练并行图例应显示 4 个阶段,分别标注为阶段 1、阶段 2、阶段 3、阶段 4。
4. 训练步骤:创建从左到右的训练流程,包含 6 个阶段:输入 Token、前向传播、损失计算、反向传播、梯度、优化器更新。包含检查点图标堆栈、“模型精度”框(提及 FP32、FP16/BF16、FP8)以及“优化器状态”框。展示梯度累积箭头,并添加说明:在训练过程中,模型预测输出、计算损失、反向传播梯度并更新权重,此过程重复数十亿次。
5. 推理服务流水线:创建紧凑的服务流程图,顶部包含 6 个阶段:用户请求、API 网关、分词器、调度器/路由器、模型服务器(GPU)、流式输出。面板内包含动态批处理(3 行请求)、模型服务器框(展示预填充与解码循环)、GPU 内存中的 KV Cache、可选适配器,以及连接 3 个模型副本的负载均衡器(标注为模型副本 1、模型副本 2、模型副本 N)。
6. 运维、可靠性与安全性:包含 6 张运维卡片,配图标:自动扩缩容、遥测/可观测性、限流与配额、安全过滤器/护栏、版本控制/回滚、成本监控。添加说明:生产级 AI 系统需要强大的运维工具以保持可靠、安全且具备成本效益。
7. 训练与推理对比:添加对比表,包含 6 行:目标、主要瓶颈、内存重点、典型指标、扩展模式、弹性需求。两列分别标注为“训练”和“推理(服务)”。训练应描述从数据中学习模型权重、分布式计算与数据移动带宽、激活值/梯度/优化器状态、每秒 Token 数或收敛速度、大批量长任务、检查点/容错。推理应描述为用户生成有用响应、延迟与吞吐量、模型权重加 KV Cache、延迟与每秒 Token 数、大量短请求、高可用性/优雅降级。
8. 右侧“关键概念”栏:创建高大的右侧边栏,标题为“关键概念”,包含 5 张带字母的卡片:A. 批大小 (Batch Size),B. 序列长度/上下文窗口,C. KV Cache,D. 吞吐量与延迟,E. 参数/权重/激活值。卡片 A 应定义批大小并展示小批量与大批量的对比(Token/人员图标)。卡片 B 应展示提示词 Token 和长上下文(标注为 T1, T2, T3, T4, …, Tn 的 Token 块)。卡片 C 应展示提示词 Token 输入紫色的圆柱形 KV Cache,随后新 Token 从缓存中读取。卡片 D 应展示 2 个仪表盘:吞吐量和延迟。卡片 E 应展示权重和激活值(蓝色与紫色网格,通过乘法连接)。在侧边栏底部添加“预填充与解码”小贴士,解释预填充处理完整提示词,而解码利用 KV Cache 逐个生成 Token。
页脚:添加底部导航条,序列为“数据 → 训练 → 推理 → 价值”,左侧配小型圆形火箭/指南针图标,并附上结束语:{argument name="footer quote" default="以数据、算力和卓越的工程能力驱动智能系统。"}
视觉风格:密集型企业技术信息图,清晰的矢量与半 3D 图标,发光的青色轮廓,微妙的渐变,体积光,小型原理图,微型图表,以及搭配现代无衬线标签的简洁衬线标题字体。配色方案应为 {argument name="color palette" default="深海军蓝、电光蓝、青色、紫罗兰色、白色及少量琥珀色点缀"}。
约束:使用 8 个带编号的主板块、5 张关键概念卡片、4 个 GPU 节点、6 个训练步骤阶段、6 个推理阶段、6 个运维卡片以及 6 行训练与推理对比表。所有可见文字保持英文,避免水印,避免品牌 Logo,并在密集布局中保持高可读性。多语言版本
AI 基础设施信息图海报
enGoal: Create a highly polished vertical educational infographic titled {argument name="headline text" default="AI INFRASTRUCTURE"} with the subtitle {argument name="subtitle text" default="HOW MODERN AI SYSTEMS WORK"}, explaining modern AI infrastructure from data pipelines and GPU training clusters to inference serving, batching, and KV cache. Canvas: Vertical poster, 4:5 aspect ratio, dark navy futuristic data-center aesthetic. Use a glowing blue/purple cyber grid background with mountains, server racks, a GPU chip illustration, neon circuit traces, thin rounded panels, white and cyan typography, and small orange numbered badges. The overall look should resemble a premium technical explainer poster, dense but readable. Layout: Large title across the top left, small subtitle and tagline below it, decorative server racks and GPU chip on the top right. Arrange the content into exactly 8 numbered main sections plus a right-side “Key Concepts” column and a bottom flow footer. Use precise panel borders, small icons, arrows, diagrams, tables, and micro-labels. Sections and required content: 1. Data Pipeline: Show exactly 5 pipeline stages connected by arrows: Raw Data Sources, Ingestion & Cleaning, Labeling / Curation, Tokenization / Chunking, and Sharding & Storage. Raw Data Sources contains exactly 5 bullets: Web pages, Documents, Code, Images, Logs. Ingestion & Cleaning contains exactly 3 bullets: Filtering, Deduplication, Normalization. Labeling / Curation contains exactly 3 bullets: Quality checks, Human / heuristic, Dataset assembly. Tokenization / Chunking contains exactly 3 bullets: Convert text to tokens, Chunk into docs, Add special tokens. Sharding & Storage contains exactly 3 bullets: Split into shards, Balanced partitions, Optimized for parallel reads. Add a caption stating that data is cleaned, deduplicated, curated, tokenized, and stored in shards so many workers can read it efficiently. 2. Storage + Orchestration Layer: Include exactly 3 vertical cards: Object Storage with a cloud-to-database icon and note “S3 / GCS / Azure Blob or on-prem object store”; Metadata / Experiment Tracking with a dashboard icon and bullets “Runs & metrics,” “Hyperparameters,” “Lineage & artifacts”; Monitoring & Logging with a chart/magnifier icon and bullets “Metrics & alerts,” “Logs aggregation,” “Tracing & debugging.” Add a footer note that the control layer coordinates compute jobs, tracks experiments, stores checkpoints, and monitors utilization, failures, and costs. 3. Training Cluster Architecture: Large central architecture diagram titled Training Cluster Architecture. Show exactly 4 GPU / Accelerator Node boxes in a 2x2 grid connected by glowing high-speed network links labeled “High-Speed Network InfiniBand / RoCE.” Each node contains CPU Host (Multi-core), RAM, GPUs such as 8x H100, and NVMe local SSD. Add dotted links between nodes. Below, include exactly 3 mini-panels: Inside a Node, Data Parallelism, and Distributed Training Parallelism (Legend). Inside a Node should show CPU connected by PCIe/NVLink/NVSwitch lines to multiple GPUs. Distributed Training Parallelism legend should show exactly 4 stages labeled Stage 1, Stage 2, Stage 3, Stage 4. 4. The Training Step: Create a left-to-right training flow with exactly 6 stages: Input Tokens, Forward Pass, Loss Compute, Backward Pass, Gradients, Optimizer Update. Include a checkpointing icon stack, a “Model Precision” box mentioning FP32, FP16/BF16, FP8, and an “Optimizer State” box. Show gradient accumulation arrows and a caption explaining that during training, the model predicts outputs, computes loss, propagates gradients backward, and updates weights, repeated billions of times. 5. Inference Serving Pipeline: Create a compact serving diagram with exactly 6 stages across the top: User Request, API Gateway, Tokenizer, Scheduler / Router, Model Server (GPU), Streamed Output. Inside the panel include Dynamic Batching with exactly 3 request rows, a Model Server box showing Prefill and Decode Loop, KV Cache on GPU Memory, optional adapters, and a load balancer connecting exactly 3 model replicas labeled Model Replica 1, Model Replica 2, Model Replica N. 6. Operations, Reliability, and Safety: Include exactly 6 operational cards with icons: Autoscaling, Telemetry / Observability, Rate Limiting & Quotas, Safety Filters / Guardrails, Versioning / Rollback, Cost Monitoring. Add a note that production AI systems need strong operational tooling to remain reliable, safe, and cost-efficient. 7. Training vs Inference: Add a comparison table with exactly 6 rows: Goal, Main Bottleneck, Memory Focus, Typical Metric, Scale Pattern, Resilience Needs. Use two columns labeled Training and Inference (Serving). Training should describe learning model weights from data, distributed compute and data movement bandwidth, activations/gradients/optimizer states, tokens per second or convergence, large batch long jobs, and checkpointing/fault tolerance. Inference should describe generating useful responses for users, latency and throughput, model weights plus KV cache, latency and tokens per second, many short requests, and high availability/graceful degradation. 8. Key Concepts right column: Create a tall right sidebar titled Key Concepts containing exactly 5 lettered cards: A. Batch Size, B. Sequence Length / Context Window, C. KV Cache, D. Throughput vs Latency, E. Parameters / Weights / Activations. Card A should define batch size and show small batch versus large batch with token/person icons. Card B should show prompt tokens and long context as token blocks labeled T1, T2, T3, T4, …, Tn. Card C should show prompt tokens feeding a purple cylindrical KV Cache, then a new token reading from cache. Card D should show exactly 2 gauges: Throughput and Latency. Card E should show weights and activations as blue and purple grids connected by multiplication. At the bottom of the sidebar add a small “Prefill vs Decode” note explaining prefill processes the full prompt and decode generates one token at a time using the KV cache. Footer: Add a bottom navigation strip with the sequence “DATA → TRAINING → INFERENCE → VALUE,” a small circular rocket/compass-style icon at left, and a closing quote: {argument name="footer quote" default="Powering intelligent systems with data, compute, and engineering excellence."} Visual style: Dense corporate technical infographic, crisp vector and semi-3D icons, glowing cyan outlines, subtle gradients, volumetric light, small schematics, miniature charts, and clean serif title typography with modern sans-serif labels. The color palette should be {argument name="color palette" default="deep navy, electric blue, cyan, violet, white, and small amber accents"}. Constraints: Use exactly 8 numbered main sections, exactly 5 key concept cards, exactly 4 GPU nodes, exactly 6 training-step stages, exactly 6 inference stages, exactly 6 operations cards, and exactly 6 training-vs-inference table rows. Keep all visible text in English, avoid watermarks, avoid brand logos, and maintain high readability despite the dense layout.
AI 基础设施信息图海报
zh-CN目标:制作一张制作精良的纵向教育信息图,标题为 {argument name="headline text" default="AI 基础设施"},副标题为 {argument name="subtitle text" default="现代 AI 系统的工作原理"},深入解析从数据流水线、GPU 训练集群到推理服务、批处理及 KV Cache 的现代 AI 基础设施。 画布:纵向海报,4:5 比例,深蓝色未来感数据中心风格。背景采用发光的蓝/紫色网络栅格,配以山脉、服务器机架、GPU 芯片插图、霓虹电路轨迹、纤细的圆角面板、白色与青色字体,以及橙色的小型编号徽标。整体外观应呈现出高端技术说明海报的质感,内容密集但易于阅读。 布局:左上方为大标题,下方为小标题和标语,右上方为装饰性的服务器机架和 GPU 芯片。将内容划分为 8 个带编号的主板块,右侧设置“关键概念”栏,底部为流程页脚。使用精确的面板边框、小图标、箭头、图表、表格和微标签。 板块及所需内容: 1. 数据流水线:展示 5 个由箭头连接的流水线阶段:原始数据源、摄取与清洗、标注/整理、分词/分块、分片与存储。原始数据源包含 5 个要点:网页、文档、代码、图像、日志。摄取与清洗包含 3 个要点:过滤、去重、归一化。标注/整理包含 3 个要点:质量检查、人工/启发式、数据集组装。分词/分块包含 3 个要点:转换为 Token、分块为文档、添加特殊 Token。分片与存储包含 3 个要点:拆分为分片、均衡分区、针对并行读取优化。添加说明文字,指出数据经过清洗、去重、整理、分词并存储为分片,以便多个工作节点高效读取。 2. 存储与编排层:包含 3 张纵向卡片:对象存储(配云到数据库图标,标注“S3 / GCS / Azure Blob 或本地对象存储”);元数据/实验追踪(配仪表盘图标,要点:“运行与指标”、“超参数”、“血缘与工件”);监控与日志(配图表/放大镜图标,要点:“指标与警报”、“日志聚合”、“追踪与调试”)。添加页脚说明:控制层负责协调计算任务、追踪实验、存储检查点并监控利用率、故障及成本。 3. 训练集群架构:中央大型架构图,标题为“训练集群架构”。展示 4 个 GPU/加速器节点框,呈 2x2 网格排列,通过发光的高速网络链路连接,标注为“高速网络 InfiniBand / RoCE”。每个节点包含 CPU 主机(多核)、RAM、GPU(如 8x H100)及 NVMe 本地 SSD。节点间添加虚线连接。下方包含 3 个小型面板:节点内部、数据并行、分布式训练并行(图例)。节点内部应显示 CPU 通过 PCIe/NVLink/NVSwitch 线连接至多个 GPU。分布式训练并行图例应显示 4 个阶段,分别标注为阶段 1、阶段 2、阶段 3、阶段 4。 4. 训练步骤:创建从左到右的训练流程,包含 6 个阶段:输入 Token、前向传播、损失计算、反向传播、梯度、优化器更新。包含检查点图标堆栈、“模型精度”框(提及 FP32、FP16/BF16、FP8)以及“优化器状态”框。展示梯度累积箭头,并添加说明:在训练过程中,模型预测输出、计算损失、反向传播梯度并更新权重,此过程重复数十亿次。 5. 推理服务流水线:创建紧凑的服务流程图,顶部包含 6 个阶段:用户请求、API 网关、分词器、调度器/路由器、模型服务器(GPU)、流式输出。面板内包含动态批处理(3 行请求)、模型服务器框(展示预填充与解码循环)、GPU 内存中的 KV Cache、可选适配器,以及连接 3 个模型副本的负载均衡器(标注为模型副本 1、模型副本 2、模型副本 N)。 6. 运维、可靠性与安全性:包含 6 张运维卡片,配图标:自动扩缩容、遥测/可观测性、限流与配额、安全过滤器/护栏、版本控制/回滚、成本监控。添加说明:生产级 AI 系统需要强大的运维工具以保持可靠、安全且具备成本效益。 7. 训练与推理对比:添加对比表,包含 6 行:目标、主要瓶颈、内存重点、典型指标、扩展模式、弹性需求。两列分别标注为“训练”和“推理(服务)”。训练应描述从数据中学习模型权重、分布式计算与数据移动带宽、激活值/梯度/优化器状态、每秒 Token 数或收敛速度、大批量长任务、检查点/容错。推理应描述为用户生成有用响应、延迟与吞吐量、模型权重加 KV Cache、延迟与每秒 Token 数、大量短请求、高可用性/优雅降级。 8. 右侧“关键概念”栏:创建高大的右侧边栏,标题为“关键概念”,包含 5 张带字母的卡片:A. 批大小 (Batch Size),B. 序列长度/上下文窗口,C. KV Cache,D. 吞吐量与延迟,E. 参数/权重/激活值。卡片 A 应定义批大小并展示小批量与大批量的对比(Token/人员图标)。卡片 B 应展示提示词 Token 和长上下文(标注为 T1, T2, T3, T4, …, Tn 的 Token 块)。卡片 C 应展示提示词 Token 输入紫色的圆柱形 KV Cache,随后新 Token 从缓存中读取。卡片 D 应展示 2 个仪表盘:吞吐量和延迟。卡片 E 应展示权重和激活值(蓝色与紫色网格,通过乘法连接)。在侧边栏底部添加“预填充与解码”小贴士,解释预填充处理完整提示词,而解码利用 KV Cache 逐个生成 Token。 页脚:添加底部导航条,序列为“数据 → 训练 → 推理 → 价值”,左侧配小型圆形火箭/指南针图标,并附上结束语:{argument name="footer quote" default="以数据、算力和卓越的工程能力驱动智能系统。"} 视觉风格:密集型企业技术信息图,清晰的矢量与半 3D 图标,发光的青色轮廓,微妙的渐变,体积光,小型原理图,微型图表,以及搭配现代无衬线标签的简洁衬线标题字体。配色方案应为 {argument name="color palette" default="深海军蓝、电光蓝、青色、紫罗兰色、白色及少量琥珀色点缀"}。 约束:使用 8 个带编号的主板块、5 张关键概念卡片、4 个 GPU 节点、6 个训练步骤阶段、6 个推理阶段、6 个运维卡片以及 6 行训练与推理对比表。所有可见文字保持英文,避免水印,避免品牌 Logo,并在密集布局中保持高可读性。