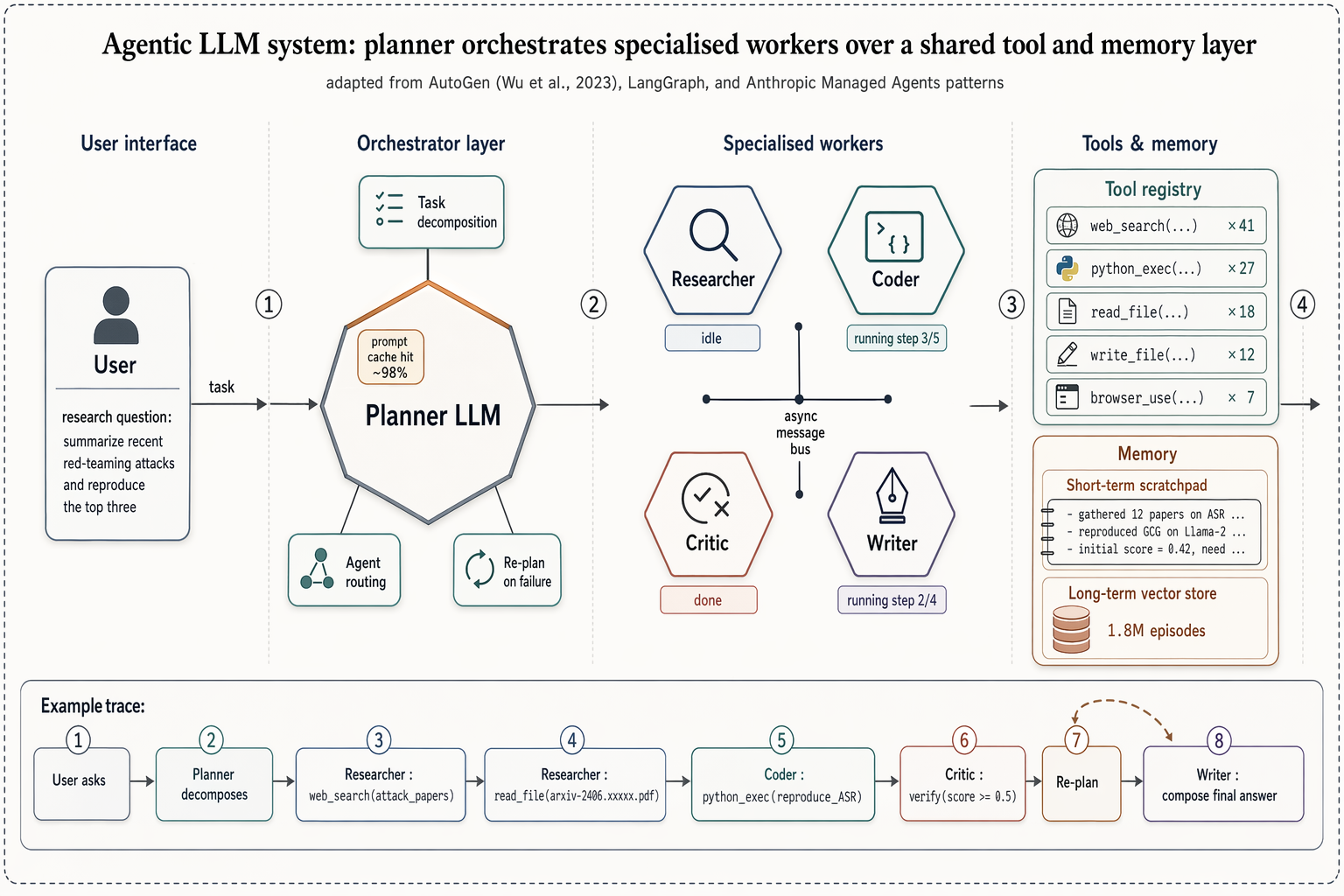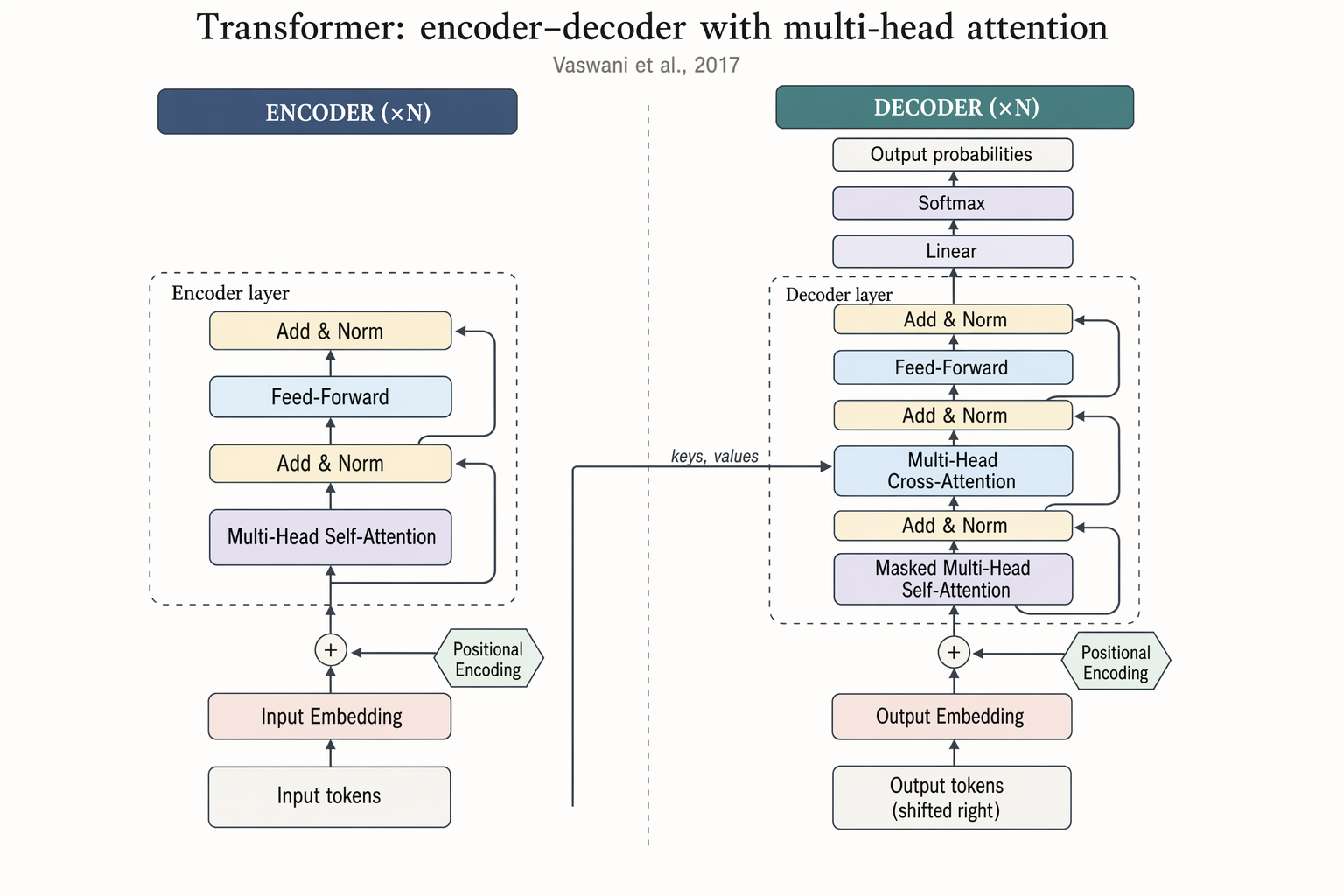
Transformer encoder–decoder architecture
Landscape 16:9 academic concept figure of the Transformer encoder-decoder architecture, NeurIPS camera-ready style. Two vertical column stacks side-by-side with a dashed divider.
- 分类
- 图表信息图
- 模型
- GPT Image 2
- 来源作者
- wuyoscar
- 原始语言
- en
- 来源 ID
- 079
完整提示词
Landscape 16:9 academic concept figure of the Transformer encoder-decoder architecture, NeurIPS camera-ready style. Two vertical column stacks side-by-side with a dashed divider. LEFT column header: "ENCODER (×N)". Blocks bottom-to-top: "Input tokens" → "Input Embedding" → "+ Positional Encoding" → dashed "Encoder layer" containing "Multi-Head Self-Attention", "Add & Norm", "Feed-Forward", "Add & Norm", with thin curved residual arrows around each sublayer. RIGHT column header: "DECODER (×N)". Blocks bottom-to-top: "Output tokens (shifted right)" → "Output Embedding" → "+ Positional Encoding" → dashed "Decoder layer" containing "Masked Multi-Head Self-Attention", "Add & Norm", "Multi-Head Cross-Attention" (horizontal arrow from encoder top labeled "keys, values"), "Add & Norm", "Feed-Forward", "Add & Norm". Above decoder: "Linear", "Softmax", "Output probabilities". Title: "Transformer: encoder–decoder with multi-head attention". Subtitle: "Vaswani et al., 2017".
多语言版本
Transformer encoder–decoder architecture
enLandscape 16:9 academic concept figure of the Transformer encoder-decoder architecture, NeurIPS camera-ready style. Two vertical column stacks side-by-side with a dashed divider. LEFT column header: "ENCODER (×N)". Blocks bottom-to-top: "Input tokens" → "Input Embedding" → "+ Positional Encoding" → dashed "Encoder layer" containing "Multi-Head Self-Attention", "Add & Norm", "Feed-Forward", "Add & Norm", with thin curved residual arrows around each sublayer. RIGHT column header: "DECODER (×N)". Blocks bottom-to-top: "Output tokens (shifted right)" → "Output Embedding" → "+ Positional Encoding" → dashed "Decoder layer" containing "Masked Multi-Head Self-Attention", "Add & Norm", "Multi-Head Cross-Attention" (horizontal arrow from encoder top labeled "keys, values"), "Add & Norm", "Feed-Forward", "Add & Norm". Above decoder: "Linear", "Softmax", "Output probabilities". Title: "Transformer: encoder–decoder with multi-head attention". Subtitle: "Vaswani et al., 2017".