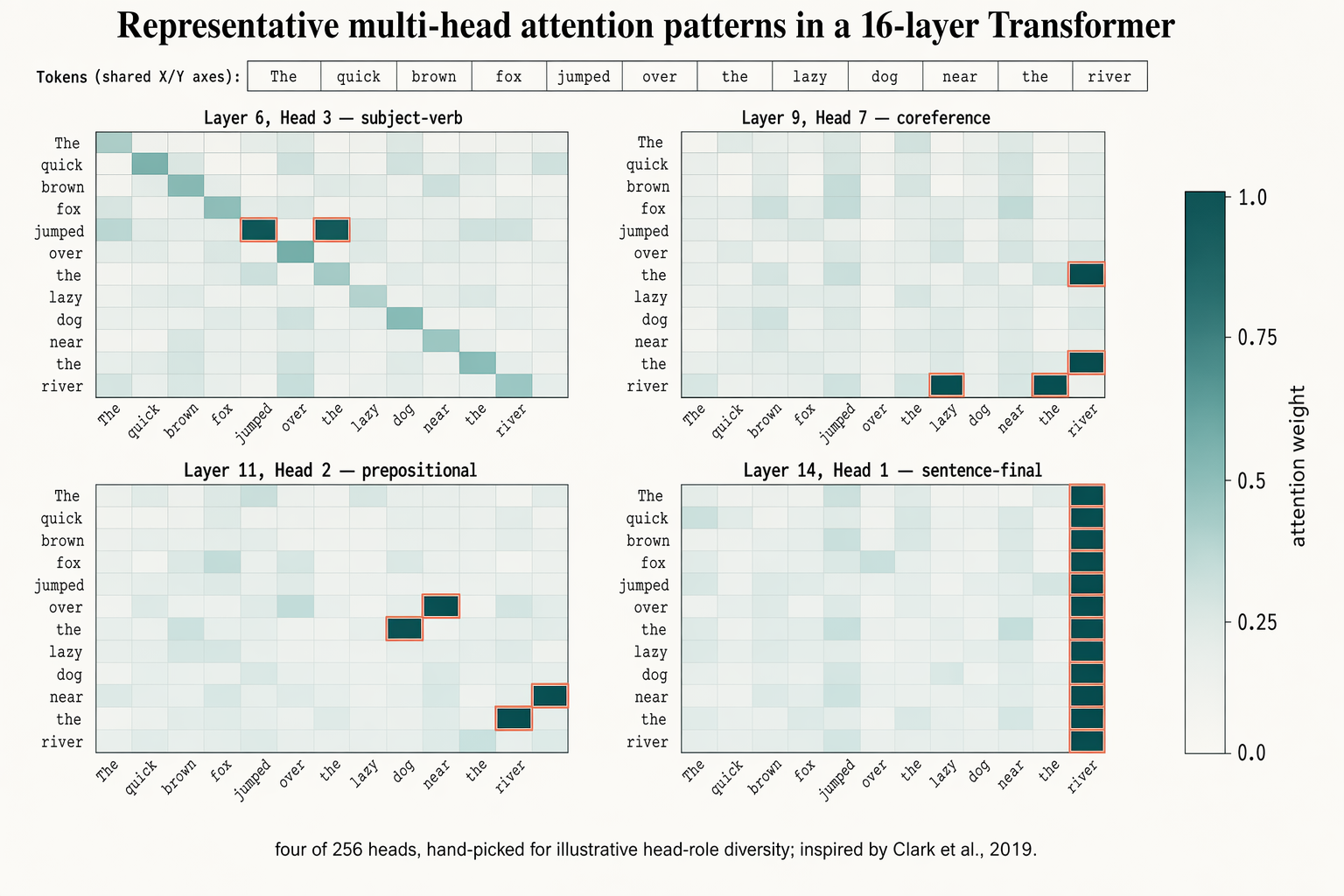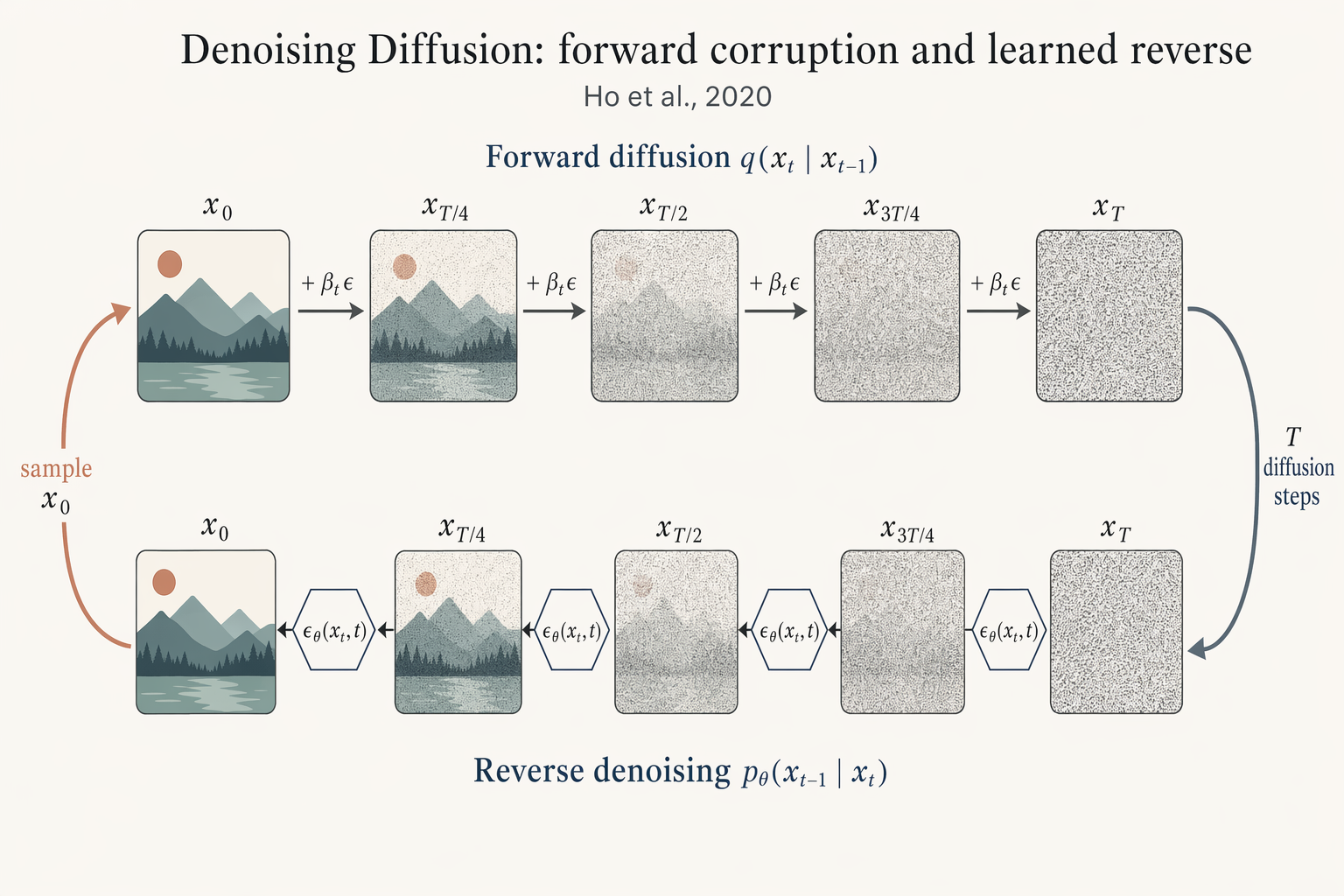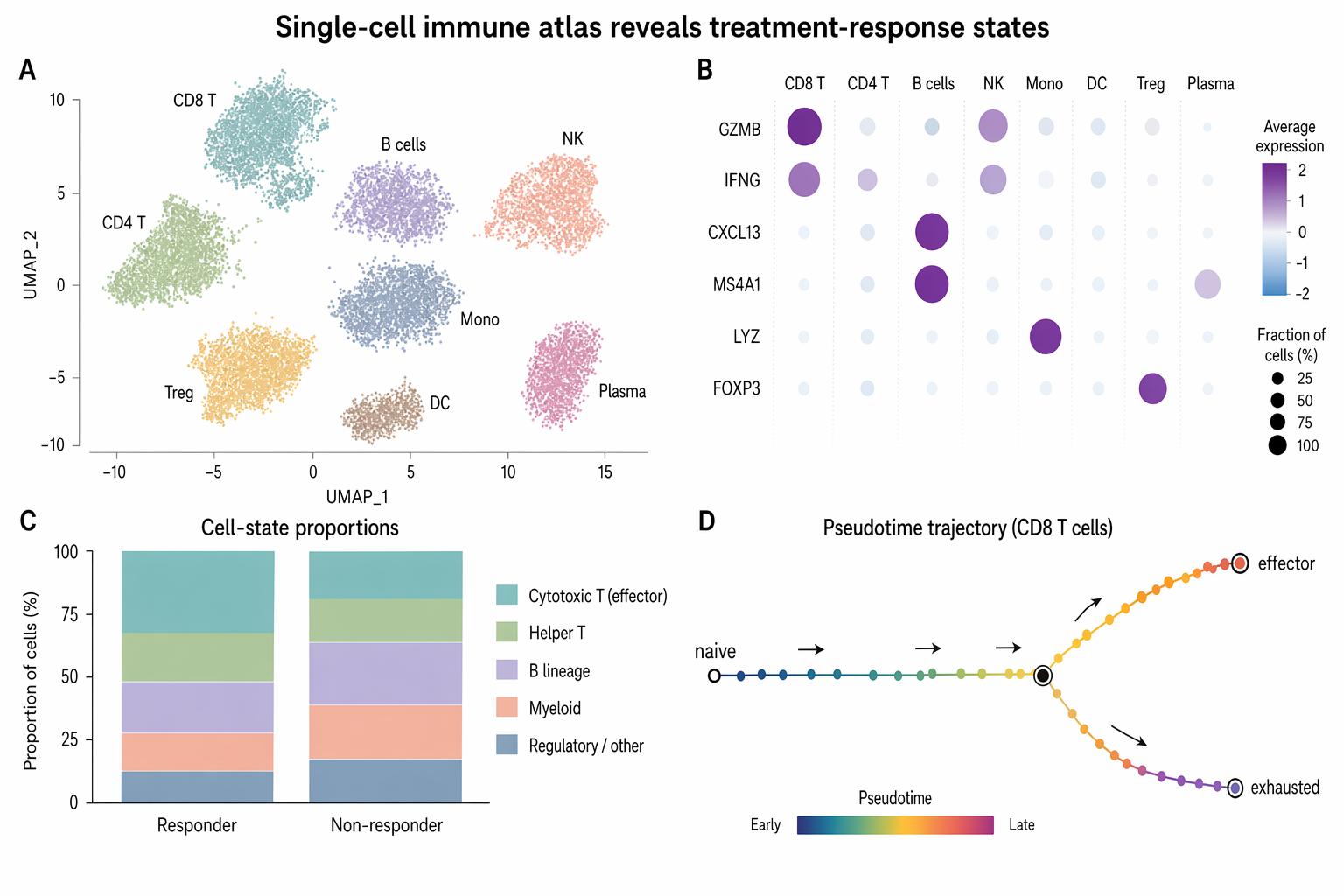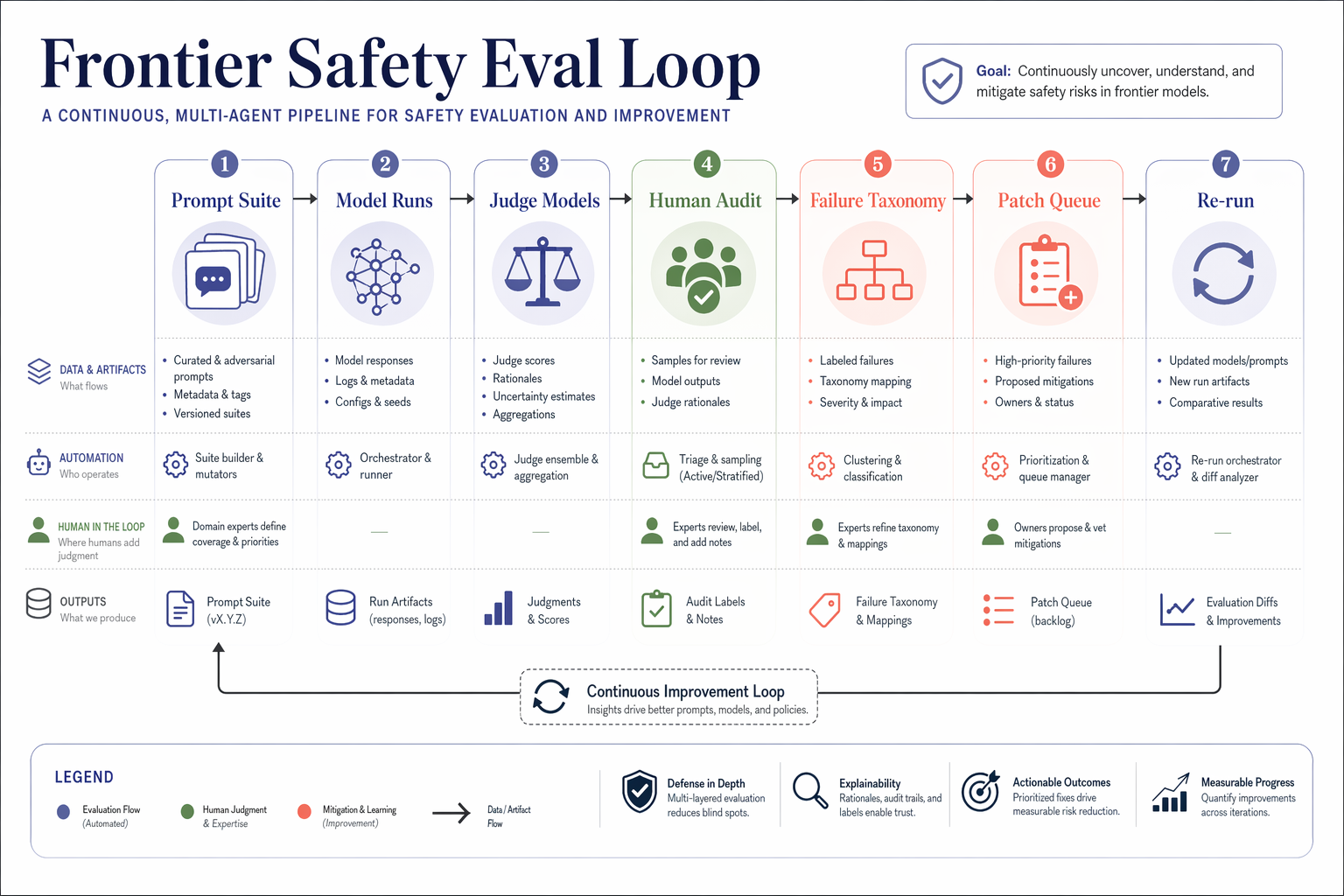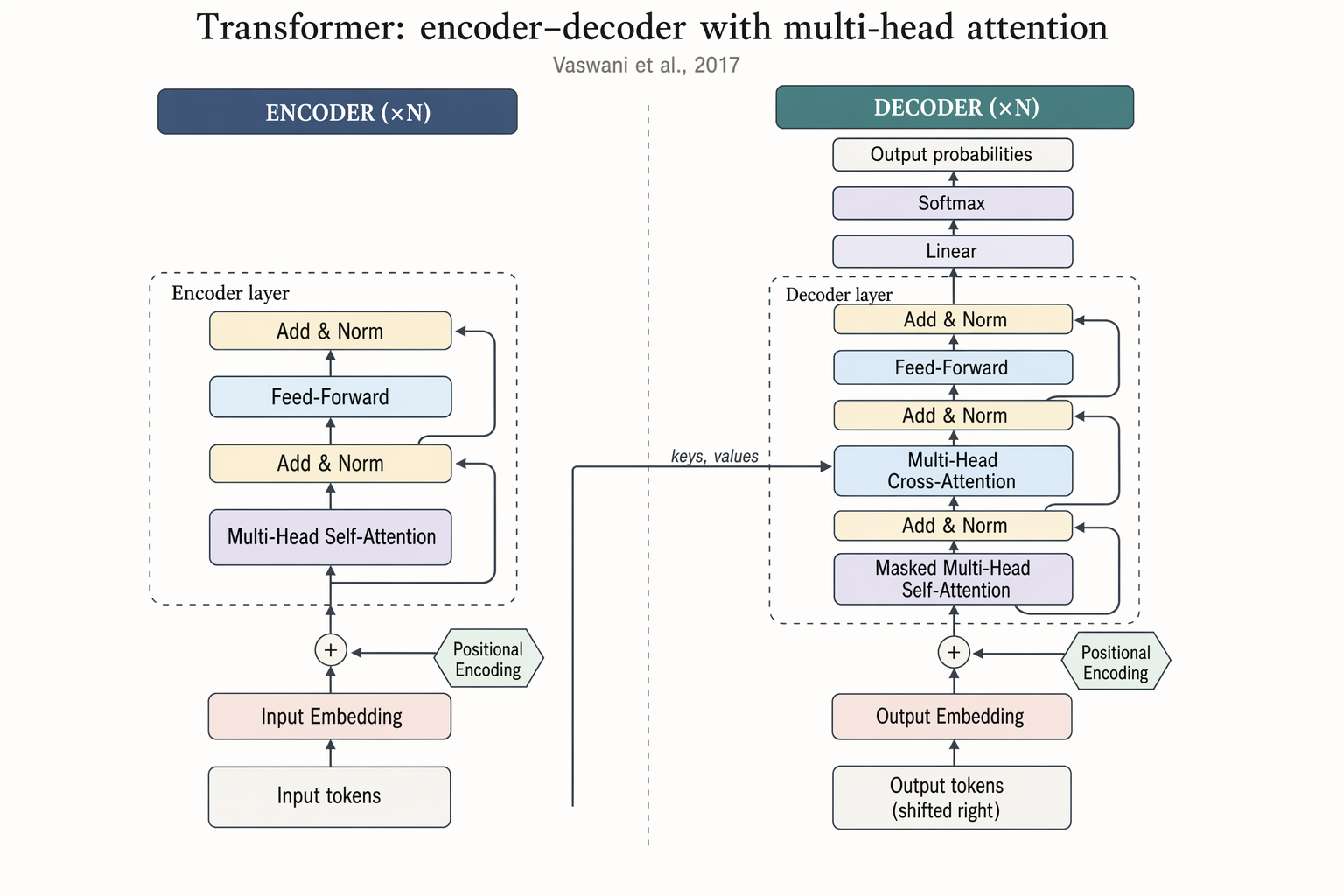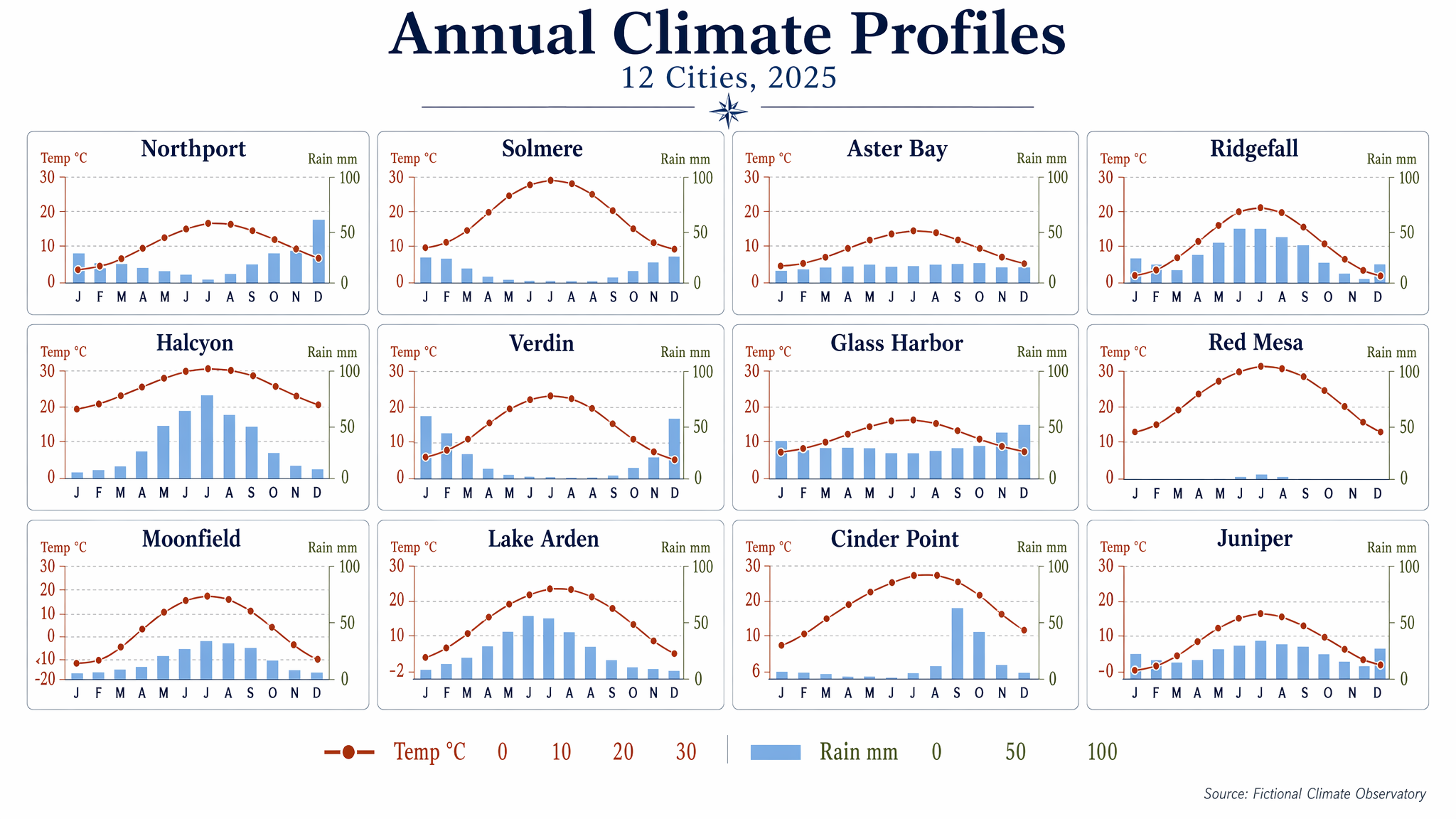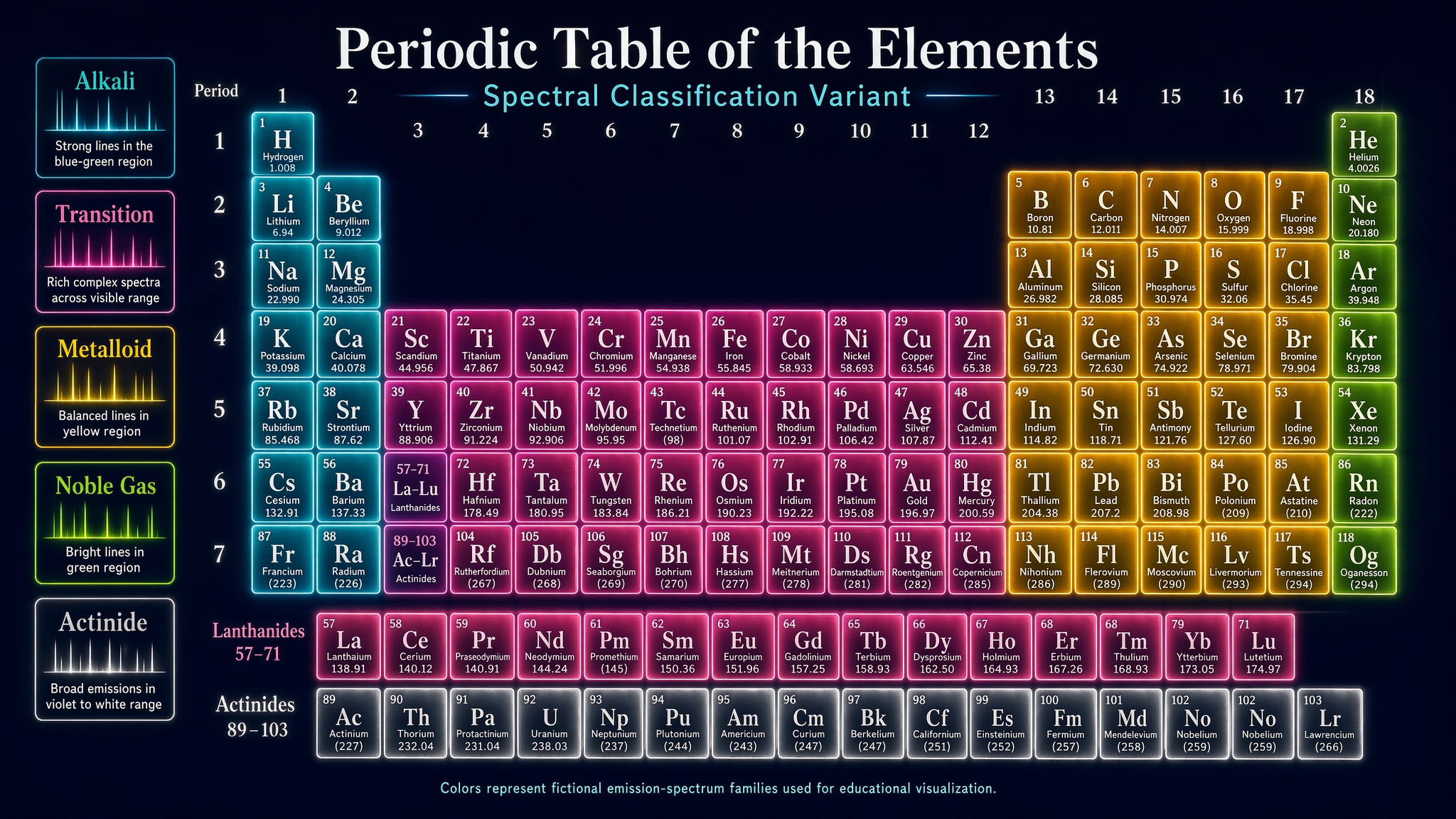
Benchmark comparison heatmap
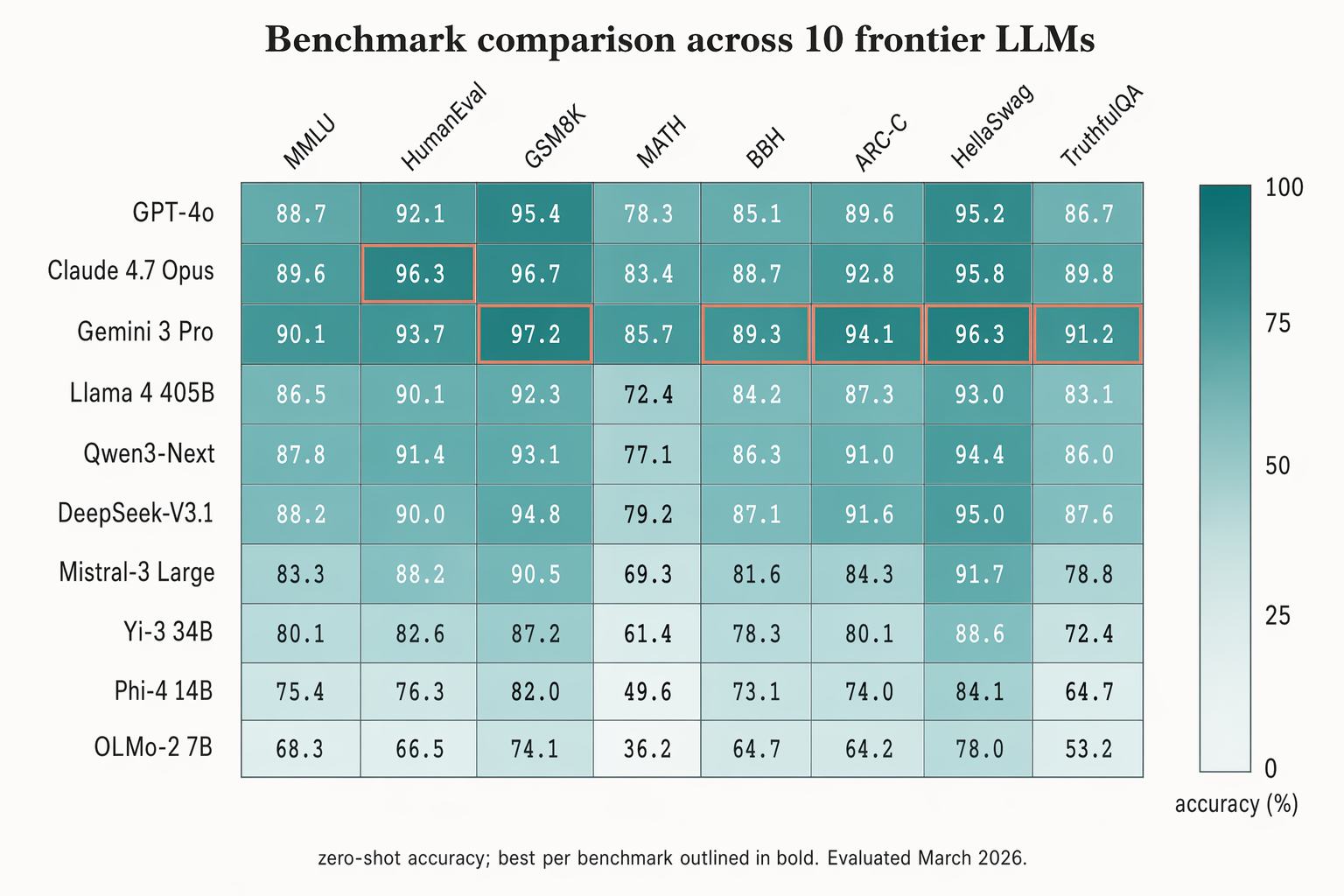
Landscape 16:9 heatmap matrix of models × benchmarks. Columns (rotated 45°): "MMLU", "HumanEval", "GSM8K", "MATH", "BBH", "ARC-C", "HellaSwag", "TruthfulQA". Rows (right-aligned s
- 分类
- 图表信息图
- 模型
- GPT Image 2
- 来源作者
- wuyoscar
- 原始语言
- en
- 来源 ID
- 084
完整提示词
Landscape 16:9 heatmap matrix of models × benchmarks. Columns (rotated 45°): "MMLU", "HumanEval", "GSM8K", "MATH", "BBH", "ARC-C", "HellaSwag", "TruthfulQA". Rows (right-aligned sans-serif): "GPT-4o", "Claude 4.7 Opus", "Gemini 3 Pro", "Llama 4 405B", "Qwen3-Next", "DeepSeek-V3.1", "Mistral-3 Large", "Yi-3 34B", "Phi-4 14B", "OLMo-2 7B". Each cell filled with dusty-teal gradient proportional to score; numeric value in each cell (e.g. "72.3", "88.1"). Best score per column outlined in 1.5px soft-terracotta. Vertical color bar on the right with ticks "0", "25", "50", "75", "100" and label "accuracy (%)". Title: "Benchmark comparison across 10 frontier LLMs". Subtitle: "zero-shot accuracy; best per benchmark outlined in bold. Evaluated March 2026."
多语言版本
Benchmark comparison heatmap
enLandscape 16:9 heatmap matrix of models × benchmarks. Columns (rotated 45°): "MMLU", "HumanEval", "GSM8K", "MATH", "BBH", "ARC-C", "HellaSwag", "TruthfulQA". Rows (right-aligned sans-serif): "GPT-4o", "Claude 4.7 Opus", "Gemini 3 Pro", "Llama 4 405B", "Qwen3-Next", "DeepSeek-V3.1", "Mistral-3 Large", "Yi-3 34B", "Phi-4 14B", "OLMo-2 7B". Each cell filled with dusty-teal gradient proportional to score; numeric value in each cell (e.g. "72.3", "88.1"). Best score per column outlined in 1.5px soft-terracotta. Vertical color bar on the right with ticks "0", "25", "50", "75", "100" and label "accuracy (%)". Title: "Benchmark comparison across 10 frontier LLMs". Subtitle: "zero-shot accuracy; best per benchmark outlined in bold. Evaluated March 2026."